- Solutions
- Platform
- Features & Benefits
- AI Powered App-Building

Leverage Knack AI to expedite your new app with just a few sentences and save hours of time.
- Security and Infrastructure

Safeguard data, control access, and ensure robust system reliability for peace of mind.
- Data Management

Organize, import, and manipulate data efficiently to make informed decisions and drive success.
- Integrations

Integrate data and workflows to enhance productivity and expand functionality effortlessly.
- Reports

Analyze data, create charts, track performance, and make data-driven decisions with ease.
- User Access

Control permissions, grant or restrict access, and ensure data security effortlessly.
- E-commerce

Sell products, manage inventory, and process payments smoothly for your e-commerce business.
- Front-End Experience

Design your app with the best experience for your users and appearance for your brand.
- Workflow

Automate data handling, trigger notifications, and simplify actions for efficient operations.
- Forms

Effortlessly build forms to collect data, leads, orders, and more.
- AI Powered App-Building
- Features & Benefits
- Resources
- Blog

- Customer Stories

- Template Marketplace

- Spreadsheet Templates

- Videos

- Learning Center

- Developer Docs

- Expert Network

- Affiliates
- Dive into Knack
- Template Apps

Expedite your app build with a pre-built template.
- Blog

Discover valuable insights and tips.
- Case Studies

Read Knack success stories.
- Spreadsheet Templates

Download and use a spreadsheet template.
- Videos

Watch testimonials, tutorials, & expert reviews.
- Template Apps
- Additional Resources
- Compare Knack

See why Knack is the best option.
- Hire an Expert Builder

Find an expert to build or expand your app.
- Learning Center

Learn about how to set up and expand your app.
- Developer Docs

Find comprehensive guides and documentation.
- Community Forum

Discuss your build with other Knack builders.
- Compare Knack
- Partner Programs
- Become An Affiliate

Increase your revenue with Knack.
- Become an Expert Builder

Get hired to build and expand apps.
- Agency Program

Resell Knack apps to clients.
- Become An Affiliate
- Blog





















- Solutions
- Platform
- Features & Benefits
- AI Powered App-Building
Leverage Knack AI to expedite your new app with just a few sentences and save hours of time.
- Security and Infrastructure
Safeguard data, control access, and ensure robust system reliability for peace of mind.
- Data Management
Organize, import, and manipulate data efficiently to make informed decisions and drive success.
- Integrations
Integrate data and workflows to enhance productivity and expand functionality effortlessly.
- Reports
Analyze data, create charts, track performance, and make data-driven decisions with ease.
- User Access
Control permissions, grant or restrict access, and ensure data security effortlessly.
- E-commerce
Sell products, manage inventory, and process payments smoothly for your e-commerce business.
- Front-End Experience
Design your app with the best experience for your users and appearance for your brand.
- Workflow
Automate data handling, trigger notifications, and simplify actions for efficient operations.
- Forms
Effortlessly build forms to collect data, leads, orders, and more.
- AI Powered App-Building
- Features & Benefits
- Resources
- Blog
- Customer Stories
- Template Marketplace
- Spreadsheet Templates
- Videos
- Learning Center
- Developer Docs
- Expert Network
- Affiliates
- Dive into Knack
- Template Apps
Expedite your app build with a pre-built template.
- Blog
Discover valuable insights and tips.
- Case Studies
Read Knack success stories.
- Spreadsheet Templates
Download and use a spreadsheet template.
- Videos
Watch testimonials, tutorials, & expert reviews.
- Template Apps
- Additional Resources
- Compare Knack
See why Knack is the best option.
- Hire an Expert Builder
Find an expert to build or expand your app.
- Learning Center
Learn about how to set up and expand your app.
- Developer Docs
Find comprehensive guides and documentation.
- Community Forum
Discuss your build with other Knack builders.
- Compare Knack
- Partner Programs
- Become An Affiliate
Increase your revenue with Knack.
- Become an Expert Builder
Get hired to build and expand apps.
- Agency Program
Resell Knack apps to clients.
- Become An Affiliate
- Blog
 Log In
Log In 
In the digital age, where information flows seamlessly across various systems and platforms, understanding the intricate processes that govern this exchange is crucial. One of the most common processes is data mapping. Whether you’re a business analyst, a developer, or a data enthusiast, grasping the significance and applications of data mapping can unlock new levels of efficiency and accuracy in handling data.
Key takeaways
- Data mapping is the process of establishing relationships between data fields in different databases or systems to ensure accurate data transfer and integration. It involves defining how data from a source system corresponds to data in a target system to facilitate seamless data migration and consistency.
- Data mapping is crucial for businesses because it ensures accurate and consistent data integration across systems, which is vital for informed decision-making and operational efficiency. It also supports data migration, compliance, and the ability to leverage data for strategic insights.
- Digital tools enhance the efficiency and flexibility of data mapping projects by automating processes, detecting schema changes, and ensuring real-time validation. They make complex data management tasks more manageable by providing features like dynamic mapping, privacy compliance, and scheduling capabilities.
What is Data Mapping?
Data mapping is the process of creating connections between different data models or structures to ensure that information is accurately transferred, integrated, and utilized across various systems. This involves defining how data fields in one database correspond to data fields in another to enable seamless communication and data consistency. It is a critical step in data management tasks such as database consolidation, data warehousing, and application integration that helps organizations maintain data integrity and improve operational efficiency.
Why is Data Mapping Important in Today’s Data-Driven World?
Data mapping is important because it ensures data accuracy and consistency across various systems. When data is transferred from one system to another, discrepancies can occur due to differences in data formats, structures, or terminologies. Data mapping helps align these differences, which is essential for decision-making processes and maintaining data integrity.
It also plays a vital role in data migration and system integration projects. As organizations upgrade or replace legacy systems, data must be transferred to new systems without loss or corruption. Effective data mapping ensures a smooth transition, reducing the risk of errors and downtime.
Additionally, in data warehousing and business intelligence initiatives, data from multiple sources must be consolidated and harmonized. Data mapping enables this by defining how data from disparate sources relate to each other, facilitating comprehensive and coherent analysis. Overall, data mapping supports robust data management practices, enhances operational efficiency, and drives informed decision-making.
What are the Benefits of Data Mapping?
Data mapping offers businesses countless data management and usability benefits, including:
- Enhanced Data Accuracy: By defining precise correspondences between data fields in different systems, data mapping minimizes errors and discrepancies, ensuring that the data remains accurate and reliable.
- Improved Data Integration: Data mapping facilitates seamless integration of data from multiple sources, enabling organizations to combine and utilize information more effectively for comprehensive analysis and decision-making.
- Efficient Data Migration: During system upgrades or replacements, data mapping ensures a smooth transition by accurately transferring data from old systems to new ones, reducing the risk of data loss or corruption.
- Increased Operational Efficiency: Data mapping can streamline data management processes, reducing the time and effort required to reconcile data from various sources and improving overall productivity.
- Better Data Consistency: Data mapping helps maintain consistency across different systems by ensuring that data is uniformly formatted and interpreted, which is crucial for maintaining data integrity.
- Enhanced Business Intelligence: By consolidating data from diverse sources into a coherent structure, data mapping supports robust data warehousing and business intelligence initiatives, enabling more insightful and actionable analysis.
- Regulatory Compliance: Accurate data mapping helps organizations meet regulatory requirements by ensuring that data is consistently and correctly managed, which is essential for audits and compliance reporting.
What are the Different Types of Data Mapping?
Each type of data mapping serves specific purposes and is suited to different scenarios, from simple data transfers to complex integration projects. Let’s take a look at the three most common types of data mapping and how they’re used.
Schema Mapping
Schema mapping is the process of aligning the data structures of different databases or systems to ensure compatibility and coherence when data is transferred or integrated. This involves defining correspondences between the schema elements of different databases, such as tables, columns, and data types, to create a unified view of the data. Schema mapping is crucial for enabling seamless data integration, data migration, and system interoperability, as it ensures that data from diverse sources can be accurately combined and utilized without loss of meaning or integrity.
Take an organization migrating data from a legacy system to a new system, for example. The legacy system and new system likely have different database schemas, with variations in table structures, column names, and data types. By employing schema mapping, the organization can define how data elements from the legacy system correspond to those in the new system. This ensures that the data migration process preserves the accuracy and consistency of the information without disrupting business operations or losing critical data.
Field Mapping
Field mapping is the process of creating direct correspondences between individual data fields in different systems or databases. This involves specifying how each field in a source data set maps to a corresponding field in a target data set. Field mapping is essential for data migration, integration, and transformation projects, as it ensures that each piece of data retains its meaning and integrity when moved between systems. This process is particularly important when dealing with disparate systems that use different naming conventions or data formats.
When integrating an existing customer relationship management (CRM) system with a new marketing automation system, for instance, the CRM system might have a field named “Cust_ID” for customer identification, while the marketing platform uses “Customer_ID.” Through field mapping, the company can establish that “Cust_ID” in the CRM corresponds to “Customer_ID” in the marketing platform. This alignment allows customer data to flow seamlessly between the systems, enhancing data accuracy and operational efficiency.
Data Transformation Mapping
Data transformation mapping is the process of defining how data should be converted or transformed as it moves from a source system to a target system. This involves specifying the rules and logic for changing the format, structure, or values of data fields to ensure compatibility and coherence between different systems. Data transformation mapping is crucial for scenarios where data needs to be reformatted, aggregated, filtered, or otherwise altered to meet the requirements of the target system or to enhance data quality and usability.
For example, an organization might want to consolidate data from various departmental databases into a central data warehouse for comprehensive analysis and reporting. Each department’s database might store date information in different formats (e.g., “MM/DD/YYYY” vs. “YYYY-MM-DD”) and use different units for measurement (e.g., pounds vs. kilograms). Through data transformation mapping, the organization can define the necessary conversions, such as standardizing date formats to “YYYY-MM-DD” and converting all weight measurements to kilograms. This ensures that the data entering the data warehouse is consistent, which facilitates effective data analysis and decision-making.
How Data Mapping Works
Now that you understand data mapping and how it’s used, let’s explore how it works. We’ve broken it down into 6 detailed steps to help you start your own data mapping project.
Step 1 – Define
The first step in data mapping is defining the data sets, tables, and other relevant structures within the source and target systems. This requires thoroughly understanding and documenting the existing data architecture to ensure a clear and accurate mapping process. To do this, you must:
- Identify Data Sources: Begin by identifying all the data sources that will be involved in the mapping process. This includes databases, spreadsheets, applications, and any other repositories where data is stored.
- Catalog Data Structures: Document the structure of each data source. This involves listing all the data sets and tables, along with their relationships and hierarchies. For databases, this means identifying the tables and their primary and foreign keys, which define how data is interconnected.
- Detail Data Fields: For each table or data set, detail the individual fields or columns. This includes noting the field names, data types, and any constraints or rules that apply (e.g., field length, mandatory fields).
- Understand Data Formats: Document the formats of the data fields, such as date formats, numerical precision, and text encoding.
- Analyze Data Relationships: Identify and document the relationships between different data sets and tables. This includes understanding how tables are linked through keys and the nature of these relationships (e.g., one-to-one, one-to-many).
Step 2 – Map the Data
The second step in data mapping is the actual process of mapping the data, which involves creating correspondences between the data elements of the source and target systems. This ensures that each piece of data in the source system is accurately matched to its counterpart in the target system. Here’s how to map your data:
- Establish Field Correspondences: Begin by matching each field in the source data set to a corresponding field in the target data set. This involves identifying fields that have the same or similar data types and meanings, ensuring that the data will be correctly interpreted in the target system.
- Define Transformation Rules: For fields that require transformation, specify the rules and logic for converting the data. This might include changing data formats, converting units of measurement, or applying calculations and functions to transform the data into the required format.
- Handle Data Type Conversions: Ensure that data type conversions are correctly handled. This is especially important when the source and target systems use different data types for the same fields, such as converting a text field in the source system to a numeric field in the target system.
- Map Relationships and Keys: Map the relationships between tables and data sets by matching primary and foreign keys. This step ensures that the relational integrity of the data is maintained
- Document Mapping Specifications: Create detailed documentation of the mapping specifications for future reference. Record each source field, its corresponding target field, any transformation rules applied, and the logic behind data type conversions.
- Validate Mapping: Perform initial validation checks to ensure that the mapping is correct and that all fields are accurately matched. This step helps identify and resolve any discrepancies or issues before the data is transferred.
Step 3 – Transformation
Data transformation is the process of converting data from its source format into the target format as defined in the mapping specifications. This is crucial for ensuring that the data is compatible with the target system and meets the necessary standards for usability and integrity. Follow these steps to transform your data:
- Apply Transformation Rules: Utilize the transformation rules defined during the mapping process to convert data into the required format. This might involve tasks such as reformatting dates, normalizing text values, aggregating data, or performing mathematical calculations.
- Ensure Data Type Consistency: Convert data types as necessary to match the target system’s requirements. For example, convert text fields to numerical fields or change string representations of dates to actual date formats recognized by the target system.
- Handle Null Values and Defaults: Address any null values or missing data in the source system by applying default values or handling them according to the target system’s requirements. This ensures that the data remains complete and meaningful after the transformation.
- Normalize Data: Normalize data values to ensure consistency. This can include converting all text to a common case (e.g., all uppercase or all lowercase), standardizing units of measurement, or ensuring consistent use of abbreviations.
- Aggregate and Filter Data: If necessary, aggregate data to create summary values or filter out irrelevant data.
- Cleanse Data: Perform data cleansing to correct errors, remove duplicates, and resolve inconsistencies. This improves data quality and ensures that the transformed data is accurate and reliable.
- Document Transformation Processes: Keep detailed records of the transformation processes, including the rules applied, data type conversions, and any issues encountered. Comprehensive documentation aids in transparency, reproducibility, and future troubleshooting.
Step 4 – Test
The fourth step in data mapping is testing, which involves verifying that the mapped and transformed data is accurate, complete, and ready for use in the target system. This helps identify and rectify any errors or discrepancies before the final deployment, ensuring data integrity and reliability. Here’s how you can effectively perform data testing:
- Develop Test Cases: Create detailed test cases that cover various scenarios, including typical data, edge cases, and potential error conditions. These test cases should be designed to validate both the correctness of the data mapping and the effectiveness of the transformations.
- Perform Unit Testing: Conduct unit tests on individual data elements and transformations to ensure that each component works as expected. This involves testing small units of the mapping and transformation logic in isolation to verify their accuracy.
- Run End-to-End Tests: Execute end-to-end tests that simulate the entire data mapping and transformation process from the source system to the target system.
- Validate Data Accuracy: To ensure accuracy, compare the transformed data in the target system against the original data in the source system. Check that all data has been correctly mapped and transformed, with no loss or corruption of information.
- Check Data Completeness: Ensure that all expected data has been transferred and transformed. This includes verifying that all records are present and that no data has been inadvertently omitted during the process.
- Test Data Consistency: Verify that data consistency is maintained throughout the mapping and transformation process. This involves checking that relationships between data elements are preserved and that any aggregations or calculations have been performed correctly.
- Review Performance and Efficiency: Assess the performance of the data mapping and transformation processes to ensure they meet required efficiency standards. This includes evaluating processing times and system resource usage to identify any potential bottlenecks or inefficiencies.
- Conduct User Acceptance Testing (UAT): Involve end-users in the testing process to validate that the data meets their needs and expectations. UAT helps ensure that the final output is user-friendly and fit for its intended purpose.
- Document Test Results: Record the outcomes of all tests, including any issues encountered and the steps taken to resolve them. Comprehensive documentation provides a clear audit trail and aids in future maintenance and troubleshooting.
- Iterate and Refine: Based on the test results, make any necessary adjustments to the data mapping and transformation logic. Iterate through the testing process until all issues are resolved and the data meets the required standards.
Step 5 – Deploy
The next step in data mapping is deployment. This ensures that the data is accurately integrated into the target system and that it functions as intended within the live operational context. Follow these deployment steps:
- Prepare the Production Environment: Ensure that the target system and its environment are fully prepared for deployment. This includes verifying system readiness, configuring necessary settings, and ensuring that all required resources are available.
- Plan the Deployment: Develop a detailed deployment plan outlining the steps to be taken, the sequence of operations, and the roles and responsibilities of the deployment team. Include contingency plans to address potential issues that may arise during the deployment.
- Backup Data: Create backups of the existing data in both the source and target systems. This step is crucial for preventing data loss and ensuring that you can restore the original data if any issues occur during the deployment.
- Execute the Deployment: Implement the data mappings and transformations in the production environment according to the deployment plan. This involves running the data migration or integration processes and applying all necessary transformations to ensure the data is accurately transferred.
- Validate Post-Deployment: After the deployment, perform validation checks to ensure that the data in the target system is accurate, complete, and consistent. Compare the post-deployment data against the original source data and the expected outcomes to verify success.
- Document the Deployment: Record all steps taken during the deployment, including any issues encountered and how they were resolved.
Step 6 – Maintain & Update
The final step in data mapping is maintenance and updating, which involves regularly monitoring and managing the data mappings and transformations to ensure ongoing accuracy, performance, and relevance. This step includes addressing any issues that arise, making necessary adjustments to accommodate changes in source or target systems, and optimizing processes to enhance efficiency. Continuous maintenance ensures that the data integration remains robust and that the systems can adapt to evolving business needs, regulatory requirements, and technological advancements.
How Tools Facilitate Data Mapping
Leveraging specialized tools like Knack can significantly enhance the efficiency and accuracy of data mapping processes. These tools offer advanced functionalities that streamline various aspects of data mapping, including:
- Schema Drift Handling: Tools automatically detect and adapt to changes in data structures, ensuring continuous and accurate data mapping despite evolving schemas.
- Parameterization and Dynamic Mapping: They allow for the use of parameters and dynamic rules, making it easier to manage and adjust mappings without extensive manual reconfiguration.
- Privacy Compliance Operations: Built-in compliance features help ensure that data mapping processes adhere to privacy laws and regulations, safeguarding sensitive information.
- Automation and Scheduling: Tools provide capabilities for automating data mapping tasks and scheduling them at regular intervals, reducing manual effort and enhancing operational efficiency.
How to Create a Data Map in 5 Easy Steps Using Knack
Mapping data using Knack can streamline your data integration process and ensure seamless data management. Follow this 5-step guide to map data effectively using Knack:
1. Set Up Your Knack Database
- Create a New App: Sign up or log in to your Knack account and create a new app or open an existing one where you want to map data.
- Define Data Structures: Set up the necessary data tables and fields that will hold your data. This involves creating objects and fields that match the structure of your source data.
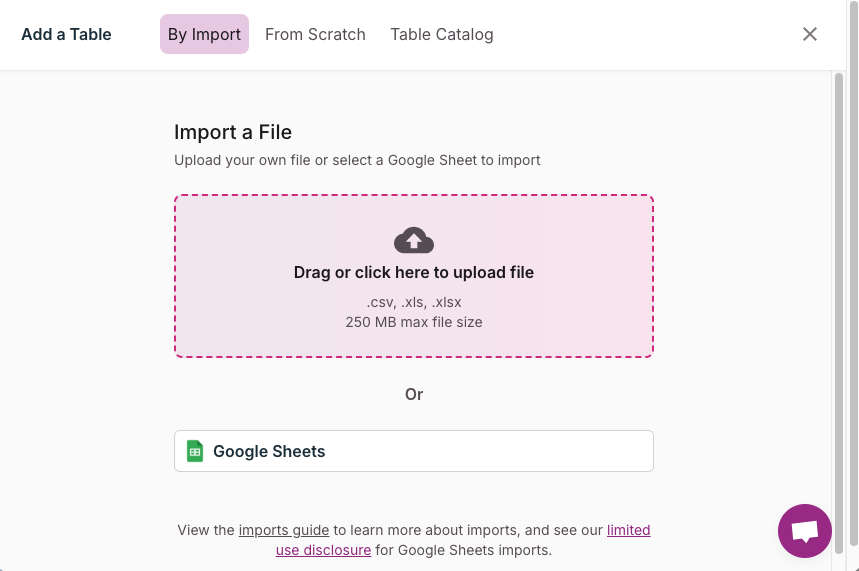
2. Import Data into Knack
- Prepare Source Data: Ensure your source data is in a format compatible with Knack, such as CSV files or Google Sheets.
- Use a Data Import Tool: Navigate to the data section of your Knack app and use the import tool to upload your source data. Map each field from your source data to the corresponding field in Knack during the import process.
3. Create Data Connections
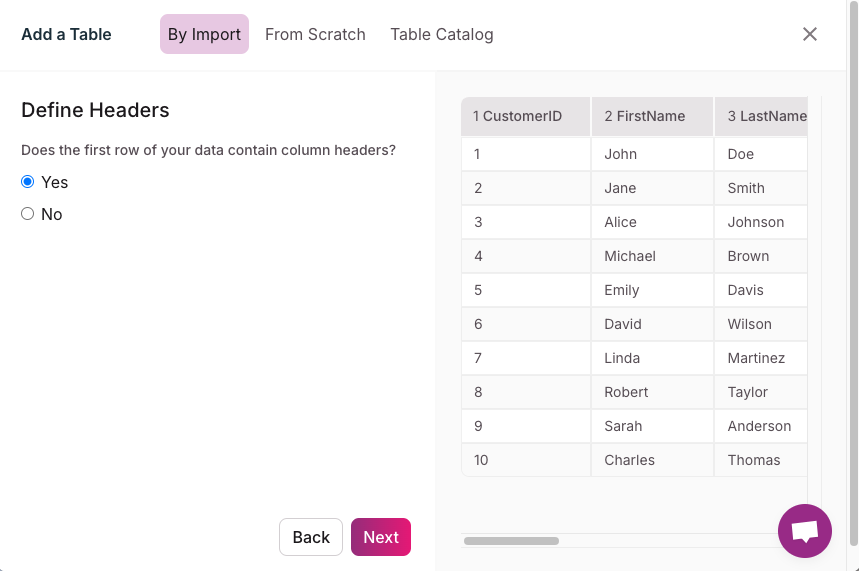
4. Map Data Fields
- Field Mapping Configuration: For each data field, configure the mapping settings to ensure that the data from the source field correctly populates the corresponding target field in Knack.
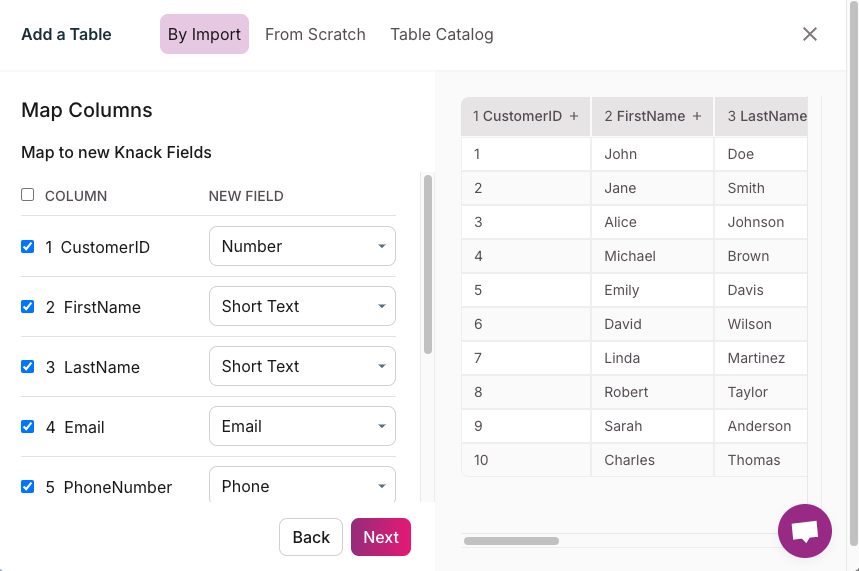
- Apply Transformations: If necessary, define transformation rules to convert data into the required format, such as date conversions, string manipulations, or numerical calculations.
- Define Relationships: Establish relationships between different objects in Knack by setting up connections. This involves linking related tables and fields to maintain data integrity and enable relational data management.
- Configure Connection Rules: Specify how data should interact between connected objects, ensuring that related records are properly associated.
5. Validate and Refine Mapping
- Test Data Mapping: Perform a test run by importing a sample of your data and verifying that it maps correctly to the target fields in Knack.
- Review and Adjust: Check the imported data for accuracy and completeness. Adjust the field mappings or transformation rules to correct any issues.
How to Troubleshoot Data Mapping Issues
Data mapping, while essential for integrating and managing data across various systems, can present several challenges. Addressing these issues is crucial to maintaining accurate and consistent data. To help you prevent data mapping issues from slowing down your project, we’ve broken down common issues and their solutions below.
Data Format Mismatches
Data format mismatches occur when the format of the data in the source system does not align with the format required by the target system, leading to errors or misinterpretations.
Solutions:
- Standardize Data Formats: Before mapping, ensure that data formats are standardized across systems. Use transformation rules to convert data into the required formats.
- Utilize Data Transformation Tools: Leverage data transformation tools that can automatically detect and convert data formats, such as date formats or numerical precision, to ensure compatibility.
- Validation Checks: Implement validation checks during the mapping process to identify and correct format mismatches before finalizing the data transfer.
Loss of Data Integrity
Loss of data integrity can occur when data is inaccurately transferred, leading to incomplete or incorrect data in the target system.
Solutions:
- Use Consistent Data Mapping: Ensure that data fields are consistently mapped between the source and target systems, preserving relationships and constraints.
- Employ Data Integrity Constraints: To maintain data integrity during the mapping process, utilize database constraints such as primary keys, foreign keys, and unique constraints.
- Regular Audits and Validations: Conduct regular audits and validations of the mapped data to detect and correct any integrity issues promptly.
Latency
Latency problems arise when there is a delay in data transfer, causing outdated or lagging data in the target system.
Solutions:
- Optimize Data Transfer Processes: Optimize the data transfer processes by using efficient algorithms and reducing the amount of data transferred in each batch.
- Implement Real-Time Data Integration: Use real-time data integration tools and techniques to ensure that data is updated in the target system as soon as it changes in the source system.
Handling Schema Changes (Schema Drift)
Schema drift occurs when changes are made to the source or target data structures, such as adding or removing fields, leading to potential mapping errors.
Solutions:
- Automatic Schema Detection: Use tools that automatically detect schema changes and adjust mappings accordingly to accommodate new or modified fields.
- Version Control: Implement version control for data schemas and mappings to track changes and ensure that updates are managed systematically.
Data Duplication
Data duplication can occur when the same data is mapped multiple times, leading to redundant records in the target system.
Solutions:
- Deduplication Processes: Implement deduplication processes to identify and remove duplicate records before and after data mapping.
- Unique Constraints: Use unique constraints and indexes in the target database to prevent duplicate entries.
- Data Quality Tools: Use data quality tools to identify and resolve duplication issues during the data mapping process.
Best Practices for Effective Data Mapping
Effective data mapping is crucial for seamless data integration and management across systems. Here are 5 key best practices to follow for successful data mapping:
- Thoroughly Understand Source and Target Systems: Conduct detailed analysis and documentation of data structures, formats, and relationships.
- Define Clear Data Mapping Rules: Create precise mapping specifications, clearly outline transformation logic, and establish validation rules to ensure data integrity and consistency.
- Utilize Automation Tools: Leverage data mapping and ETL tools for automated field matching, real-time validation, and efficient data extraction, transformation, and loading processes.
- Implement Robust Testing and Validation: Develop comprehensive test cases, perform unit and end-to-end testing, and validate all mapping and transformation steps to ensure accuracy.
- Maintain Ongoing Monitoring and Maintenance: Regularly monitor performance, update mappings for system changes, and conduct data quality audits to ensure long-term data integrity and accuracy.
Final Thoughts on Data Mapping
Data mapping is a fundamental process in data management and integration. It enables organizations to ensure data accuracy, consistency, and usability across different systems. As data continues to grow in volume and complexity, mastering data mapping becomes increasingly crucial for maintaining data integrity and driving operational efficiency.
Ready to kickstart your data mapping project? Sign up with Knack and start building for free today!







